Quality data is at the heart of quality research. The scholarly community depends on valid, reliable, and easily accessible data in order to empirically test our theories of social and political processes. Yet quantitative data is not “truth” in an absolute sense, but rather, is a numeric representation of complex phenomena. For conflict researchers, the challenge of collecting quality data is particularly acute given the nature of our enterprise.
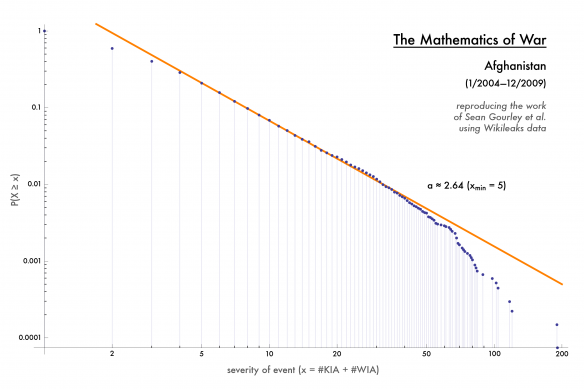
A graph of the frequency and severity of violent incidents in Afghanistan. By Max Braun.
Given the costs and risks involved, it is practically impossible to observe every battle, civilian massacre, human rights violation, or protest event. Therefore, we often rely upon other sources — journalists, non-governmental organizations, truth commissions, and so on — to report on key features of a conflict, then turn such information into numeric values. Turning such reports into data isn’t a trivial task, but requires digesting large amounts of text, sorting through often-conflicting information, making judgments about coding rules, and dealing with ambiguous cases.
Recently, there have been a number of conversations in the conflict studies community about the challenge of collecting data that is accurate, replicable, and inter-operable with existing data. One such discussion occurred during a workshop held at the 2013 Annual Meeting of the International Studies Association in San Francisco, where several key figures from leading data collection projects were gathered. Some of the key concepts and ideas from that workshop were recently turned into a series of short articles, just published as a special feature of the Journal of Peace Research. In that special feature, scholars discuss their own experiences (good and bad) with collecting data, updates on current data projects, and practical tools for future data collection, all with an eye on common standards and best practices (for an exemplary discussion of best practices, see this paper by Christian Davenport and Will Moore).
Read more in the post at Political Violence @ A Glance.